CONTENTS
Code can be found here
Deployed model here
Making a classifier which can distinguish Seoul from Munich and Sanfrancisco! (hoping my well in Munich!)
Creating dataset from google images
In machine learning, you always need data before you build your model.
You can use either URLs or google_images_download package. Since Jeremy explained specifically, I will try the other.
Using google_images_download
note: This is not google official package
Refer to Official Doncument, put that arguments.
from google_images_download import google_images_download
response = google_images_download.googleimagesdownload() #class instantiation
out_dir = os.path.abspath('../../materials/dataset/pkg/')
os.mkdir(out_dir)
arguments = {"keywords":"Cebu,Munich,Seoul",
"print_urls":True,
"suffix_keywords":"city",
"output_directory":out_dir,
"type":"photo",
}
paths = response.download(arguments) #passing the arguments to the function
print(paths)
and if you need, here is main code.
Create ImageDataBunch
We need to separate validation set because we just grabbed these imagese from Google.
Most of the dataset we use (kaggle/research) splited into train / validation / test
so if they are not devided beforehand we should make databunch, and Jeremy recommended assign 20% to validation.
Help on function verify_images in module fastai.vision.data:
verify_images(path: Union[pathlib.Path, str], delete: bool = True, max_workers: int = 4, max_size: int = None, recurse: bool = False, dest: Union[pathlib.Path, str] = '.', n_channels: int = 3, interp=2, ext: str = None, img_format: str = None, resume: bool = None, **kwargs)
Check if the images in `path` aren't broken, maybe resize them and copy it in `dest`.
Data from google image url
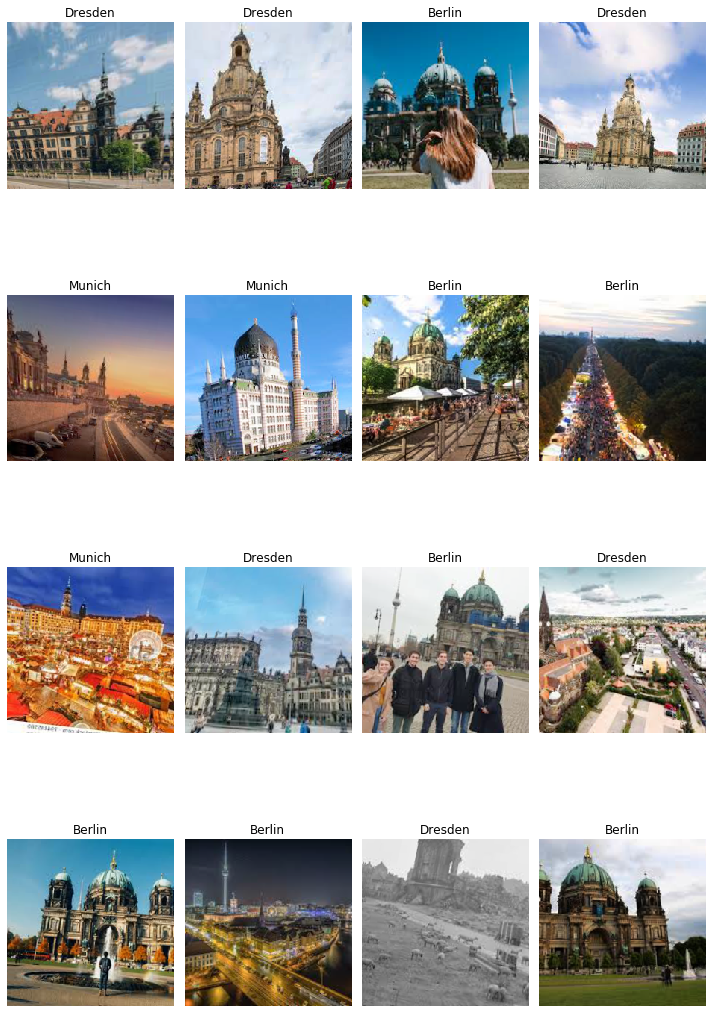
Data from package

Train model
| len(class) | len(train) | len(valid) | |
|---|---|---|---|
| Data_url | 3 | 432 | 108 |
| Data_pkg | 3 | 216 | 53 |
Uisng model: restnet34 1, Measurement: accuracy 2
fit_one_cycle()
What is fit one cycle?
Cyclical Learning Rates for Training Neural Networks
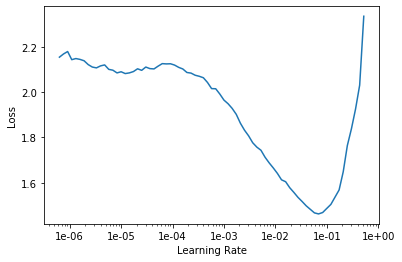
One of the way to find good learning rate. Core idea is to start with small learning rate (like 1e-4, 1e-3) and increase the learning rate after each mini-batch till loss starts exploding. And pick up learning rate one order lower than exploding point. For example, plotted learning rate is like below picture, picking up around 1e-2 is the best way.
Why this methods
Traditionally, the learning rate is decreased as the learning starts converging with time. But this paper suggests to cycle our learning rate, because it makes us avoid local minimum. Basically this cyclic method enables us to explore whole of loss function so that find out global minimum. In other words, higher learning rate behaves like regularisation.
Let’s find-tune
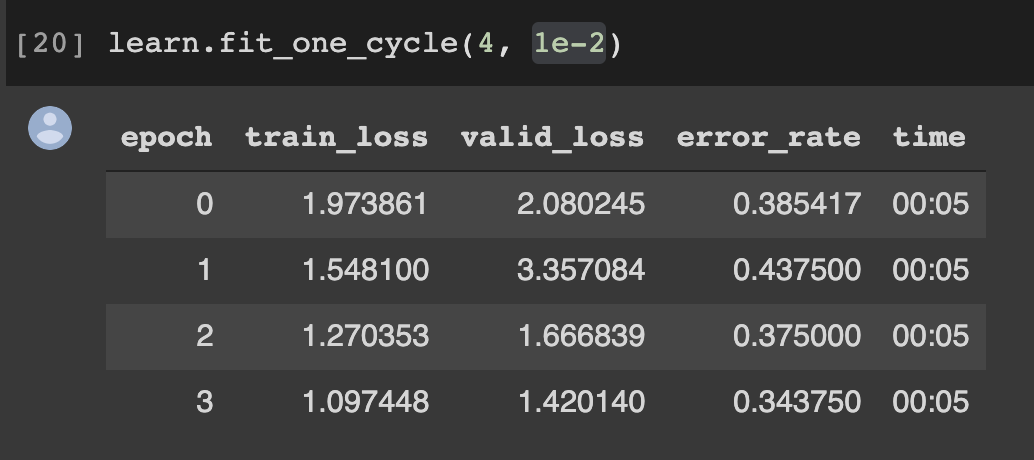
Do train just one last layer by learning rate found by find_lr
This section you should find the strongest downward slope that kind of sticking around for quite a while. And choose just one order lower than lowest point. As explained before, I will pick up 1e-2. And of course, this is fine-tuning, we don’t need discriminative learning rate yet.
Let’s train the whole model!
When you plot the learning rate again, maybe you will get soaring shape of learning rate. Rule of thumb, When you slice the learning rate, use learning rate you used at unfrozen part. Divide it by 5 or 10 and put it on maximum bound. At minimum bound, get the point just before it soared, and divide it by 10.
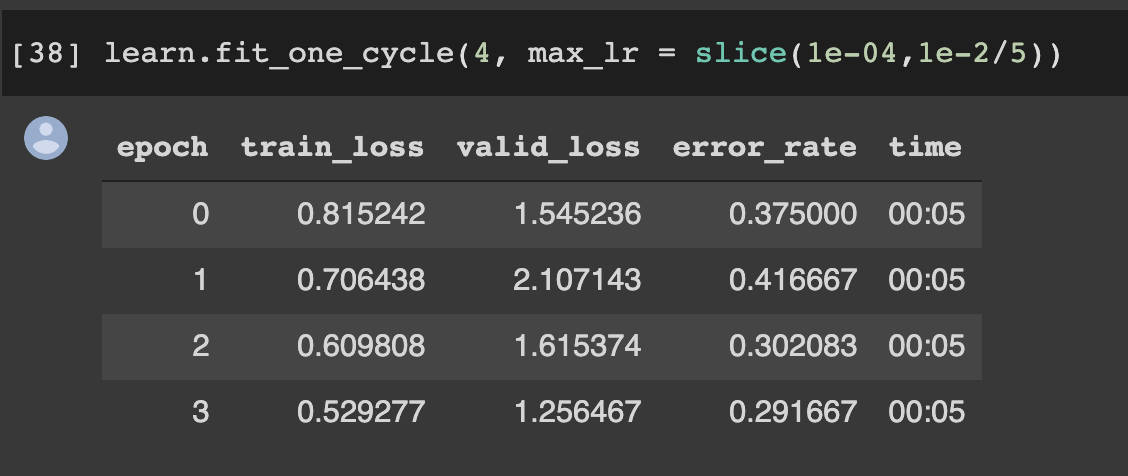
Let’s make batch size bigger!
Since default batch size is 64, I tried it to 128. And it gets way more better result(even it’s still underfitting!)
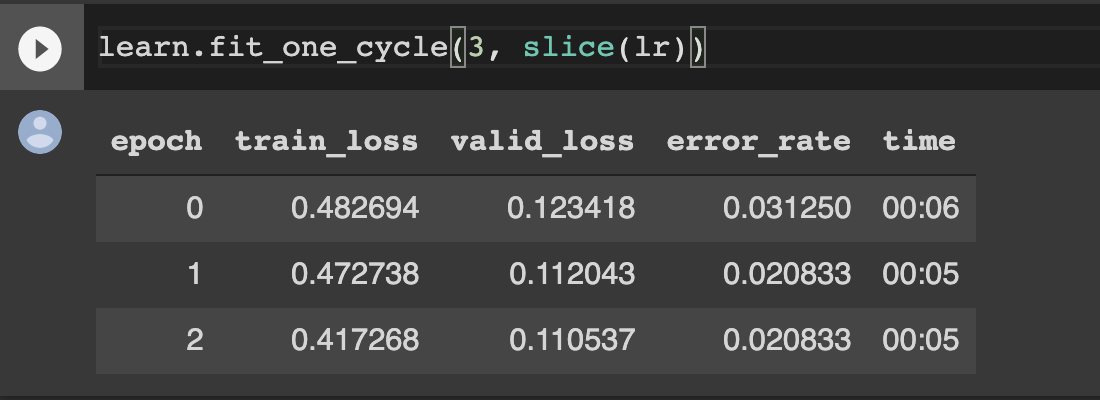
And if I freeze model and train whole model again, the model would be better. Also, you can use this method to the other big dataset model training!
Interpretation
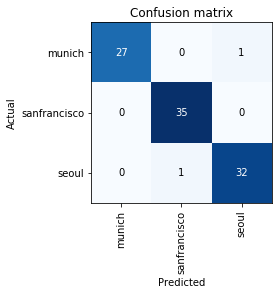
See the confusion matrix. Result is quite great.
*Since I’m using colab, I will skip data cleansing. But I highly recommend you to use ImageCleaner widget, only if you are using jupyter notebook (not jupyter lab)
Model in production
You can deploy your model in simple way. I referred fast.ai, and used render(it’s free for limited time). You can find detailed document here.
and you can create a route like this.
@app.route("/classify-url", methods=["GET"])
async def classify_url(request):
bytes = await get_bytes(request.query_params["url"])
img = open_image(BytesIO(bytes))
_,_,losses = learner.predict(img)
return JSONResponse({
"predictions": sorted(
zip(cat_learner.data.classes, map(float, losses)),
key=lambda p: p[1],
reverse=True
)
})
You can find my deployed model here
 Digital Product School week 5
Digital Product School week 5