Most of the code and model architecture come from a paper Attention is all you need and a repository of fastai
Question
Embeddings
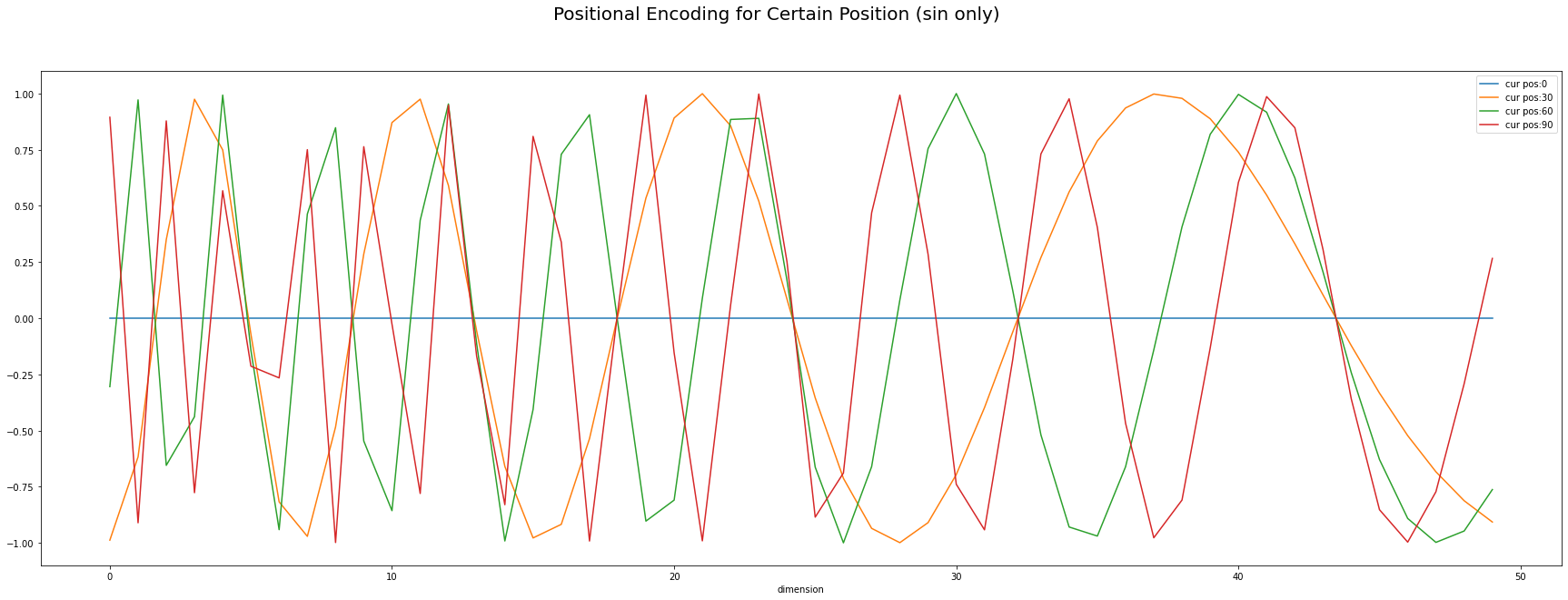
📝 🎮 Q1. Explain what does Positional Encoding do in your words. Implement transformer positional encoding, which corresponds to following figure. And plot both cosine and sine graph given positional information. (see paper section 3.5)
![]()
🎮 Q2. Implement transformer input embedding, which corresponds to following figure. (see paper section 3.5)
![]()
feed-forwrad
🎮 Q3. Implement position-wise feed-forward networks (see paper section 3.3)
📝 🎮 Q4. Explain how does multi-head self-attention work in your own words and implement it.
📝 🎮 Q5. Explain why do we need masking in your own words and implement it.
Q6. Implement Encoder (which has mha -> feed-forward) and Decoder blocks
Q7. Implement whole Transformer model
Answer
A1.
class PositionalEncoding(nn.Module):
def __init__(self, d_model:int):
super().__init__()
self.register_buffer('freq', 1/(10000 ** (torch.arange(0, d_model, 2.))))
def __call__(self, pos):
inp = torch.outer(pos, self.freq)
enc = torch.cat([inp.sin(), inp.cos()], dim=-1)
return enc📝 As the paper described, a sequential information is not handled by the model, the authors substituted it alternative mechanism which is composed of sinusoidal functions to handle that information.
However, as of Jan 2022, many paper reported that positional encoding does not affect the performance. Of course it depends on specifics 😉.
positions = torch.arange(0, 100).float(); positions[:10]
d_model = 26 # original paper set this value to 512
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2,1, figsize=(20,10))
fig.suptitle("Positional Encoding", fontsize=30)
res = PositionalEncoding(d_model=d_model)(positions)
for i in range(0,3):
ax[0].plot(res[:,i], label=f"sin, cur pos:{i}")
ax[0].legend()
ax[0].set_xlabel("relative posotion")
ax[1].plot(res[:,int(d_model/2+i)], label=f"cos, cur pos:{i}"); ax[1].legend()
A2
import math
class TransformerEmbedding(nn.Module):
def __init__(self, vocab_size:int, emb_size:int, drop_p:float=0.):
self.emb_size = emb_size
self.embed = nn.Embedding(vocab_size, emb_size)
self.pos_enc = PositionalEncoding(emb_size)
self.dropout = nn.Droupout(drop_p)
def forward(self, input):
"input : sequence of indices of input sentence. e.g., [54, 23, 43, 12, 4, 4, 892, ...]"
pos = torch.arange(0, input.size(1), device=input.device)
return self.dropout(self.embed(input) * math.sqrt(self.emb_size) + self.pos_enc(pos))
2 last line of TransformerEmbedding.forward(), in self.embed(input) * math.sqrt(self.emb_size) + self.pos_enc(pos)
A3
def feedforward(d_model:int, d_ff:int, ff_p=0., double_drop=None):
layers = [nn.Linear(d_model, d_ff), nn.ReLU()]
if double_drop: layers.append(nn.Dropout(ff_p))
return SequentialEx(*layers, nn.Linear(d_ff, d_model), MergeLayer(), nn.LayerNorm())
class MergeLayer(nn.Module):
"Merge a shortcut with the result of the module by adding them or concatenating them if `dense=True`."
def __init__(self, dense:bool=False): self.dense=dense
def forward(self, x): return torch.cat([x,x.orig], dim=1) if self.dense else (x+x.orig)
class SequentialEx(nn.Module):
"Like `nn.Sequential`, but with ModuleList semantics, and can access module input"
def __init__(self, *layers): self.layers = nn.ModuleList(layers)
def forward(self, x):
res = x
for l in self.layers:
res.orig = x
nres = l(res)
# We have to remove res.orig to avoid hanging refs and therefore memory leaks
res.orig, nres.orig = None, None
res = nres
return res
def __getitem__(self,i): return self.layers[i]
def append(self,l): return self.layers.append(l)
def extend(self,l): return self.layers.extend(l)
def insert(self,i,l): return self.layers.insert(i,l)
SequentialEx and MergeLayer - skip connection (from resnet) or densenet3 4
A4
📝
- each word in an input embedding has their own query, key, value parameters.
- A query of each word maps sets of key-value pairs into output. As illustrated at a below image, q1 maps (k1, v1) ,…, (kn, vn), where
n=n_heads, into an output by weighed summation, and finally z1. z1, z2, …, zm are stacked vertically (where m =n_words) which corresponds to a single head (shape:n_wordsxd_heads).
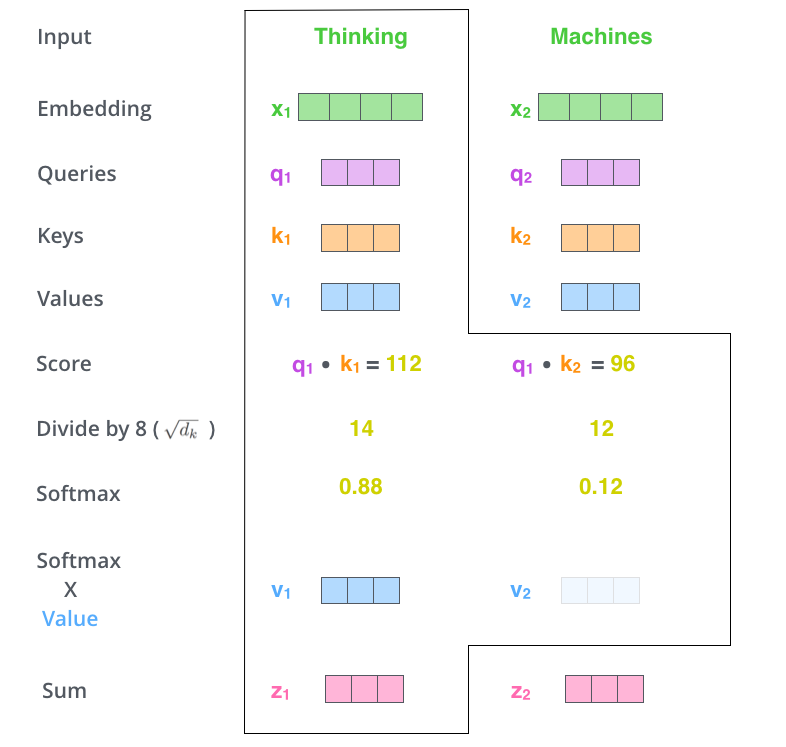
Image Source: The Illustrated Transformer
🎮
class MultiHeadAttention(nn.Module):
"MutiHeadAttention."
def __init__(self, n_heads:int, d_model:int, d_head:int=None, resid_p:float=0., attn_p:float=0., bias:bool=True,
scale:bool=True):
super().__init__()
d_head = ifnone(d_head, d_model//n_heads)
"Note that d_head can be decided arbitrarily"
self.n_heads,self.d_head = n_heads,d_head
self.q_wgt = nn.Linear(d_model, n_heads * d_head, bias=bias)
self.k_wgt = nn.Linear(d_model, n_heads * d_head, bias=bias)
self.v_wgt = nn.Linear(d_model, n_heads * d_head, bias=bias)
self.out = nn.Linear(n_heads * d_head, d_model, bias=bias)
self.drop_att,self.drop_res = nn.Dropout(attn_p),nn.Dropout(resid_p)
self.ln = nn.LayerNorm(d_model)
self.scale = scale
def forward(self, q:Tensor, k:Tensor, v:Tensor, mask:Tensor=None):
return self.ln(q + self.drop_res(self.out(self._apply_attention(q, k, v, mask=mask))))
def _apply_attention(self, q:Tensor, k:Tensor, v:Tensor, mask:Tensor=None):
"""a shape of q, k, v is identical, which is (bs, seq_len, d_model)"""
bs,seq_len = q.size(0),q.size(1)
# Projection to dq, dk, and dv, where output tensor shape = (bs, seq_len, n_heads * d_head)
wq,wk,wv = self.q_wgt(q),self.k_wgt(k),self.v_wgt(v)
# reshaping to (bs, seq_len, n_heads, d_head)
wq,wk,wv = map(lambda x:x.view(bs, x.size(1), self.n_heads, self.d_head), (wq,wk,wv))
# reshaping from (bs, seq_len, n_heads, d_head) to
# query: (bs, n_heads, seq_len, d_head)
# key: (bs, n_heads, d_head, seq_len)
# value: (bs, n_heads, seq_len, d_head)
wq,wk,wv = wq.permute(0, 2, 1, 3), wk.permute(0, 2, 3, 1), wv.permute(0, 2, 1, 3)
# (bs x n_heads x seq_len x d_head)
# matmul (bs x n_heads x d_head x seq_len)
# => attention score: (bs x n_heads x seq_len x seq_len)
attn_score = torch.matmul(wq, wk)
# if scale => div by sqrt of d_head
if self.scale: attn_score = attn_score.div_(self.d_head ** 0.5)
if mask is not None:
attn_score = attn_score.float().masked_fill(mask, -float('inf')).type_as(attn_score)
# (bs x n_heads x seq_len x seq_len),
# , where attn_prob[0,:,0] : (n_heads x seq_len)
# represents all scaling factors for one query(i.e., a word) with respect to all words in a sequence
# In other words, attn_prob[0,:,0] represents Figure 3 of Attention is all you need
attn_prob = self.drop_att(F.softmax(attn_score, dim=-1))
# (bs x n_heads x seq_len x d_head)
attn_vec = torch.matmul(attn_prob, wv)
# (bs x seq_len x n_heads x d_head)
return attn_vec.permute(0, 2, 1, 3).contiguous().contiguous().view(bs, seq_len, -1)
def _attention_einsum(self, q:Tensor, k:Tensor, v:Tensor, mask:Tensor=None):
# Sylvain Gugger: Permute and matmul is a little bit faster but this implementation is more readable
bs,seq_len = q.size(0),q.size(1)
wq,wk,wv = self.q_wgt(q),self.k_wgt(k),self.v_wgt(v)
# reshaping to (bs, seq_len, n_heads, d_head)
wq,wk,wv = map(lambda x:x.view(bs, x.size(1), self.n_heads, self.d_head), (wq,wk,wv))
# matmul to (bs x seq_len x seq_len x n_heads)
attn_score = torch.einsum('bind,bjnd->bijn', (wq, wk))
if self.scale: attn_score = attn_score.mul_(1/(self.d_head ** 0.5))
if mask is not None:
attn_score = attn_score.float().masked_fill(mask, -float('inf')).type_as(attn_score)
# Note: matmul to (bs x seq_len x seq_len x n_heads)
attn_prob = self.drop_att(F.softmax(attn_score, dim=2))
attn_vec = torch.einsum('bijn,bjnd->bind', (attn_prob, wv))
return attn_vec.contiguous().view(bs, seq_len, -1)
A5
📝 There are two reasons.
- To prevent model from cheating future sequences (as it’s not recurrent) 6
- To make model not take care of padding.
🎮
def get_padding_mask(inp, pad_idx:int=1):
return None
return (inp == pad_idx)[:,None,:,None]
def get_output_mask(inp, pad_idx:int=1):
return torch.triu(inp.new_ones(inp.size(1),inp.size(1)), diagonal=1)[None,None].byte()
return ((inp == pad_idx)[:,None,:,None].long() + torch.triu(inp.new_ones(inp.size(1),inp.size(1)), diagonal=1)[None,None] != 0)
# Example of mask for the future tokens:
torch.triu(torch.ones(10,10), diagonal=1).byte()
A6
class EncoderBlock(nn.Module):
"Encoder block of a Transformer model."
#Can't use Sequential directly cause more than one input...
def __init__(self, n_heads:int, d_model:int, d_head:int, d_inner:int, resid_p:float=0., attn_p:float=0., ff_p:float=0.,
bias:bool=True, scale:bool=True, double_drop:bool=True):
super().__init__()
self.mha = MultiHeadAttention(n_heads, d_model, d_head, resid_p=resid_p, attn_p=attn_p, bias=bias, scale=scale)
self.ff = feed_forward(d_model, d_inner, ff_p=ff_p, double_drop=double_drop)
def forward(self, x:Tensor, mask:Tensor=None): return self.ff(self.mha(x, x, x, mask=mask))
class DecoderBlock(nn.Module):
"Decoder block of a Transformer model."
#Can't use Sequential directly cause more than one input...
def __init__(self, n_heads:int, d_model:int, d_head:int, d_inner:int, resid_p:float=0., attn_p:float=0., ff_p:float=0.,
bias:bool=True, scale:bool=True, double_drop:bool=True):
super().__init__()
self.mha1 = MultiHeadAttention(n_heads, d_model, d_head, resid_p=resid_p, attn_p=attn_p, bias=bias, scale=scale)
self.mha2 = MultiHeadAttention(n_heads, d_model, d_head, resid_p=resid_p, attn_p=attn_p, bias=bias, scale=scale)
self.ff = feed_forward(d_model, d_inner, ff_p=ff_p, double_drop=double_drop)
def forward(self, x:Tensor, enc:Tensor, mask_in:Tensor=None, mask_out:Tensor=None):
y = self.mha1(x, x, x, mask_out)
return self.ff(self.mha2(y, enc, enc, mask=mask_in))
A7
class Transformer(nn.Module):
"Transformer model"
def __init__(self, inp_vsz:int, out_vsz:int, n_layers:int=6, n_heads:int=8, d_model:int=256, d_head:int=32,
d_inner:int=1024, inp_p:float=0.1, resid_p:float=0.1, attn_p:float=0.1, ff_p:float=0.1, bias:bool=True,
scale:bool=True, double_drop:bool=True, pad_idx:int=1):
super().__init__()
self.enc_emb = TransformerEmbedding(inp_vsz, d_model, inp_p)
self.dec_emb = TransformerEmbedding(out_vsz, d_model, 0.)
self.encoder = nn.ModuleList([EncoderBlock(n_heads, d_model, d_head, d_inner, resid_p, attn_p,
ff_p, bias, scale, double_drop) for _ in range(n_layers)])
self.decoder = nn.ModuleList([DecoderBlock(n_heads, d_model, d_head, d_inner, resid_p, attn_p,
ff_p, bias, scale, double_drop) for _ in range(n_layers)])
self.out = nn.Linear(d_model, out_vsz)
self.out.weight = self.dec_emb.embed.weight
self.pad_idx = pad_idx
def forward(self, inp, out):
mask_in = get_padding_mask(inp, self.pad_idx)
mask_out = get_output_mask (out, self.pad_idx)
enc,out = self.enc_emb(inp),self.dec_emb(out)
for enc_block in self.encoder: enc = enc_block(enc, mask_in)
for dec_block in self.decoder: out = dec_block(out, enc, mask_in, mask_out)
return self.out(out)
A8
def seq2seq_collate(samples:BatchSamples, pad_idx = 1, pad_first:bool=True, backwards:bool=True):
"return items to data "
samples = to_data(samples)
"get max length of data to initialize (bs x seq_len)"
max_len_x, max_len_y = max([len(o[0] for o in samples)]), max([len(o[1] for o in samples)])
res_x = torch.zeros(len(samples), max_len_x)
res_y = torch.zeros(len(samples), max_len_y)
"if there's backward pass, change pad_first to pad_last"
if backwards: pad_first = not pad_first
for i, s in enumerate(samples):
if pad_first:
"forward i.e., left to right sequence of text, fill in right empty parts"
res_x[i,-len(s[0]):], res_y[i,-len(s[1]):] = LongTensor(s[0]), LongTensor(s[1])
else:
"backward i.e., right to left sequence of text, fill in left empty parts"
res_x[i,:len(s[0]):], res_y[i,:len(s[1]):] = LongTensor(s[0]), LongTensor(s[1])
if backwards: res_x, res_y = res_x.flip(1), res_y.flip(1)
return res_x, res_y
Note
- Sylvain Gugger suggests two exactly same ways of implementing multi-head attention.
_apply_attention- permute and matmul, not readable but faster-
_attention_einsum- einsum, readable but slower - Here
attn_score = torch.matmul(wq, wk)doesn’t fit to broadcasting logic.- Because
wqis a (bs x n_heads, seq_len, d_head) andwkis a (bs x n_heads x d_head x seq_len) tensor where last two dimensions are different. - According to pytorch docs, v.10.1, the out will be a (bs x n_heads x seq_len x seq_len) tensor.
- Okay, I understand why, but how?
- The document explains that it only looks at the batch dimension when determining if the inputs are broadcatable. That is said, we can think of the calculation of an attention score where
queryis (bs, n_heads, seq_len, d_head) and thekeyis (bs, n_heads, d_head, seq_len) as thequeryis (bs, n_heads, seq_len, d_head,1) and thekeyis (bs, n_heads,1, d_head, seq_len) - Then the out will be (bs x n_heads x seq_len x seq_len) which is the projection from
d_headdimension toseq_lendimension.
- Because
- Using
attn_probof_apply_attention9, you can visualize Figure 3 to Figure 5 of the paper Attention is All You Need.- Figure 3:
attn_prob[0, :, 0, :], i.e., align score from all multi-heads, w.r.t., first word.
- Figure 3:
- Top, Figure 4:
attn_prob[0, 4, :, :], i.e., full attention for head 5 - Bottom, Figure 4:
attn_prob[0, 4:6, 8, :], i.e., isolated attentions from just the word ‘its’ for attention heads 5 and 6.- Here I choose ninth word following the order in he Figure 4.
- Figure 5:
attn_prob[0, i, :, :], here i in range(0, n_heads), two of them. The authors did not specify the exact indices.
- The best explanation I’ve read by far, from ptrblck - https://discuss.pytorch.org/t/contigious-vs-non-contigious-tensor/30107/2
- Explaining in my words,
.contiguousis in need because we want to fit the memory layout of the tensor to the shapes and strides of tensor. - When do we need it? when we want to restore the layout (e.g., flatten!).
- Explaining in my words,
Footnotes
-
Q. Why half cosine and half sine? ↩
-
Q. How can we add two tensors?
self.pos_enc(pos)is a shape of (len(pos), emb_size: d_model) and self.embed(input) is a shape of (bs, len(words in one document), emb_size:d_model). Considering it does broadcasting, how can we guaranteelen(words in one document) == len(pos)? ↩ -
Q. I don’t understand why we need additional
res, and how thoseres,nres, andxchange. A. => think ofresas an agent of actualx. This another agent is need for keeping value of x consistent. Throughout these layers[nn.Linear, nn.Relu, nn.Dropout, nn.Linear, Mergelayer, nn.Layernorm], each layer gets tensor that has a.origattribute for the original x. OnlyMergeLayeruses that attribute. And I think this shares similar design pattern with CallBack. ↩ -
Q. I don’t understand why do we need
nres.orig = None. It seemsnresdoes not haveorigattribute, thus no need of removing. For example, if i test following code,x = torch.randn(200,50); x.orig = x; a = DummyLayer()(x); a.orig, this will returnAttributeErroras output tensor does not have that attribute. // New question(Update: 2022-03-08), I do not know why do we neednres↩ -
In
MultiHeadAttention, why do we need to add query (seereturn self.ln(q + self.drop_res(self.out(self._apply_attention(q, k, v, mask=mask)))), i.e., residual net), though we have aMergeLayer? -> it was feedforward that we implementedMergeLayer, and we need another residual connection forMultiHeadAttention↩ -
but should we have to mask it when it’s recurrent model? or do we mask it because there is no recursion? -> My initial answer is yes, cuz when you are doing processing sequence recurrent, it means you are autoregressively referring to time steps provided beforehand. So the information might be regulated. ↩
-
For the whole architecture, why is it using
LayerNorminstead ofBatchNorm? ↩ -
- Why do we
drop_last? Why do we needno_check?- Why do wedrop_last? Why do we needno_check?
- Why do we
-
The arrange of axies between
_apply_attentionand_attention_einsumis different. ↩
 Part2 lesson 11, 07a Layer-wise Sequential Unit Variance Initialization | fastai 2019 course -v3
Part2 lesson 11, 07a Layer-wise Sequential Unit Variance Initialization | fastai 2019 course -v3