Note of lesson7 : Deep Learning Part 1 of Spring 2019 at USF, version 3 course
Today we will study lots of things so don’t be frustrated.
- ResNets
- Unets
- GANs
- RNNs
CONTENTS
@reshama at fastai forum, who deployed app using fastai both of ios and android version.
- lesson7-resnet-mnist.ipynb
- lesson3-camvid.ipynb
- lesson7-suprres-gan
- lesson7-wgan
- lesson7-superres
- RNNs
(#f) what do learn
lesson7-resnet-mnist.ipynb
data block API
pillow’s convert mode L, which is grey scale
items attribute is kind of the thing we get from data
binary color map, refer to matplotlib for more info
remember that pytorch put channel first
you have to say how to split (when using fastai lib)
validation is (of course) has labels
1) have itemlist 2) split it 3) label it
y are category object for now mnist
transforms
- kind of digit, you don’t want to rotate or flip since it will change the digit’s meaning
So Jeremy added random crop and added padding
[]: empty is transforms for validation set, no need for transform for validation set.
we don’t use pre-trained model, so we don’t need image net stats. (#f)
plot_multi can show you results of calling some function, which grab the dataset, how many transformed version we create?: infinite, each time we call it, we grab the new transformed dataset.
(batch_size, channel, row, col)
Basic CNN with batchnorm
nn.Conv2d(ni, nf, kernel_size = 3, stride=2, padding=1)
how many channels you want? -> as much as you want
(#f)
(1,8) -> one channel coming in, 8: how many filters you want to come out
conv(ni, nf) <- ni, nf is input / output channel
so as a result, 10 by 1 by 1 (which means grid size is 1)
careful of the comment, which represents grid size
it decreases by half since stride = 2
Refactor
exactly the same neural net.
how can we improve this?
Resnet-ish
Deep Residual Learning for Image Recognition - skip connection, identity, res block
- Motivation of the paper: 56 layer is way more worse than the 20-layer(shallow) network.
- Idea: keep the 56 layers but make results identical with shallow version
- How:
a building block, every two convolutions, add the results together with input
and this became legendary architecture
Visualising the Loss Landscape of Neural Nets
- x, y - weight space, y - loss
- without identity connection, it’s very bumpy and with res connection, and this is little bit similar with batch norm.
except the last one, jeremy added res block without last layer.
don’t forget to refactor your code
.9954, and NIPS 2015 the best paper was 0.45% error - sota changes so fast
MergeLayer
SequentialEx : Sequential extended (#f)
and real code, we don’t add, but concat. and this is dense net.
- memory intensive because how deep you go in, you have original data, but very little parameter (#q) (#f)
really work well for segmentation
(#f) re-building the modern architecture, and he keep trying to show …..(#f)
lesson3-camvid.ipynb
in order to color cluster, it has to know what that it is
A guide to convolution arithmetic for deep learning - great picture show what does 3 by 3 half stride conv looks like.
U-net, down sampling path. size keep decreasing, channels keep increasing. And at last the grid size came back to same.
Then, how do we double the grid size?
stride - half convolution -> transposed convolution, deconvolution,
and this is maybe 1, 2 years ago. why?
- nearly all of the pixel is zero
- different amount of information to the different convolution path (see the paper, and understand myself)
Solution: (1) Nearest neighbour interpolation
- just copy twice, no zero, no computation.
(2) bilinear interpolation - weighted average (this is pretty standard with picture)
- kind of skip connection but not added to the every 2 conv block, but to the same stage of the downsampling to the same stage of the upsampling
see the code how fastai implemented this
encoder refers to the downsampling part, which is substituted with resnet
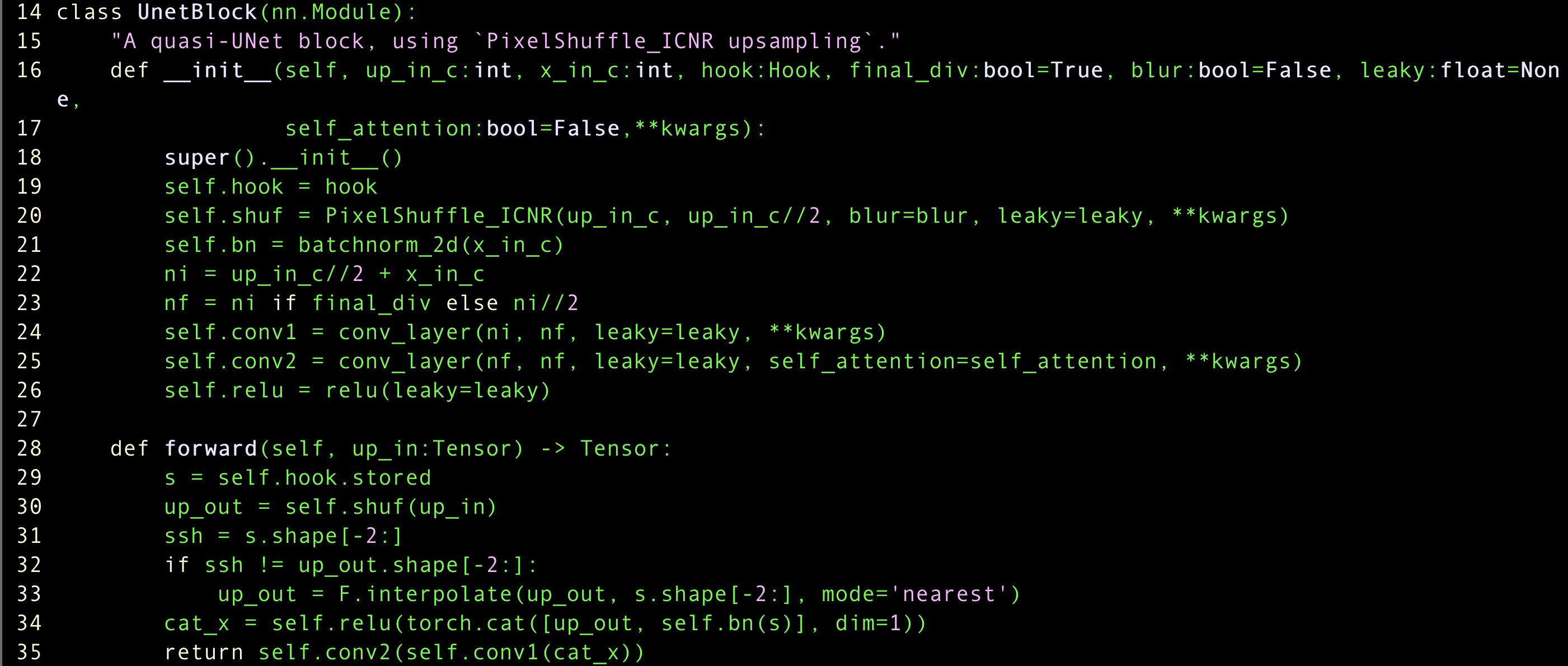
unet_block is connection between the up-sampling and down-sampling
class UnetBlock
they grab the hook, to use resnet, and up_out using up-sampling
each time you see two convolutions like conv2(conv1()), you can think of what if I add the res block? probably you would get a better results.
identity connection is done with 1) add 2) concat
Q. why call concat before conv1, conv2 and not after? (#q - see the code) / J: there’s no way to interact with channel (???) remember if you do 2 conv, it’s actually 3d, (#f)
Q. size of image feature layer changes, how does dense net work since it concatenate. / J: ?? (#f) 53:00:00
lesson7-suprres-gan
will use to another task, image restoration, which starts from the image but will make better image, like black-white to color, resolution, .. (#f)
Crappified data
paraLLeL(crappify, il.items)
fastai’s function which does crappification(it takes time quite much)
we gonna use, pre-trained model, since we added some noise and we have to catch what original picture was., which is watermark removal
use MESLoss, and it normally expects two vectors, which can compare so we flat version.
pre-trained part of unet is down-sampling part.
GANs
Motivation of GAN: Our loss function doesn’t represent what we want.
- we are missing the texture of pillow, blanket
-> the emergent of GAN. it uses another models(Critic, discriminator) for loss function
t = 3761 » Jeremy explaination of GAN
cons: if you don’t have pre-trained Critic/Generator, it’s kind of blind vs blind
Save generated images
let’s create Critics
(#q) reconstruct = True
we will learn more of what’s going on inside at part2
if you don’t want to re-initiate the gpu ram, you can gc.collect() which will remove caching gpu.
we will use Binary Cross Entropy but will not use resnot
- Because of weight could be increased much that we can’t handle that, but will learn at part2
we should be careful when using gan, loss which uses adaptive loss
we not only use the critic to loss function, but also MSE loss because if we use only the Critics as loss function, generator could make irrelevant photo of the original image.
GANs hates momentum. - but nobody figured it out.
tough things of training gan - loss number is meaningless. / so you have to see the results from time to time
(original craffied picture / generated picture / original picture)
Q. What kind of task you will not use U-net? / J: Unet is used when size of output is aligned to the input. so any kind of generative modelling and segmentation is also generative modelling because we should out pixel segments which is responding to original pixel. and it would be absurd if we use unet to the classification, because we just need the down-sampling process.
lesson7-wgan
(skipped so fast…)
interesting because we use bedrooms dataset
the approach that we use is ‘can we create a bedroom?’
we feed the generator random noise
and generator should return the de-noised bedroom.
lesson7-superres
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
doesn’t like the term ‘perceptual’ - jeremy prefers to say it is feature losses
down-sampling part is called encoder, and vice versa
same color represents same grid size
(#f) explained idea but could not get. - t=5022
pick the l1 loss or mse ( no matter)
grad is false since we will use only the loss
class featureloss is the implementation of the paper
(abandoned to write -> too hard…. and too fast)
upsize medium res data, and you can see the pixels enlarged focus.
results is quite good
- the student of fast.ai, made colored picture who had the fast.ai course.
(#f) and also said lots of idea related to this. we can new way of Crappification.
Q. how about using unet or gan to nlp, kind of generating shakespear’s novel. / J: possible, and it’s quite blue ocean, and will look thorough little bit at part2
Be sure not to understand at once, go through this at least 3 times or more
RNNs
- square - input / arrow - layer / circle - activation / triangle - output
go to the learn.summary and see the specifics
we will do mat mul and non-linearity one(or more) more, but (??) will use same weight.
bptt - back prop through time
13017 / 70 / bs - all dataset divide first by batch size, and after that, divide by length limit (but why??????)
every mini-batch joins up with previous mini-batch (that’s why he showed textify)
how we convert the diagram to the code
rnn is just a refactoring, there’s nothing new.
-> but only just predicting last word is wasteful, so we will predict every word, which means just triangle comes inside the model.
maintain state
Let’s keep the hidden state.
(rnn is totally normal nn but just refactored)
nn.RNN
this time we will render the output the other loop, which is nn.RNN
bptt 20 means 20 layers of the diagram.
2-layer GRU
there are small nn which decide how much apply the nodes.
GRU/lstm is depended on specifics
 Part1 lesson6 note | fastai 2020 course-v4
Part1 lesson6 note | fastai 2020 course-v4