CONTENTS
- 02a_why_sqrt5.ipynb
- 02b_initializing.ipynb
- 03_minibatch_training.ipynb
- 04_callbacks.ipynb
- 05_anneal.ipynb
02a_why_sqrt5.ipynb
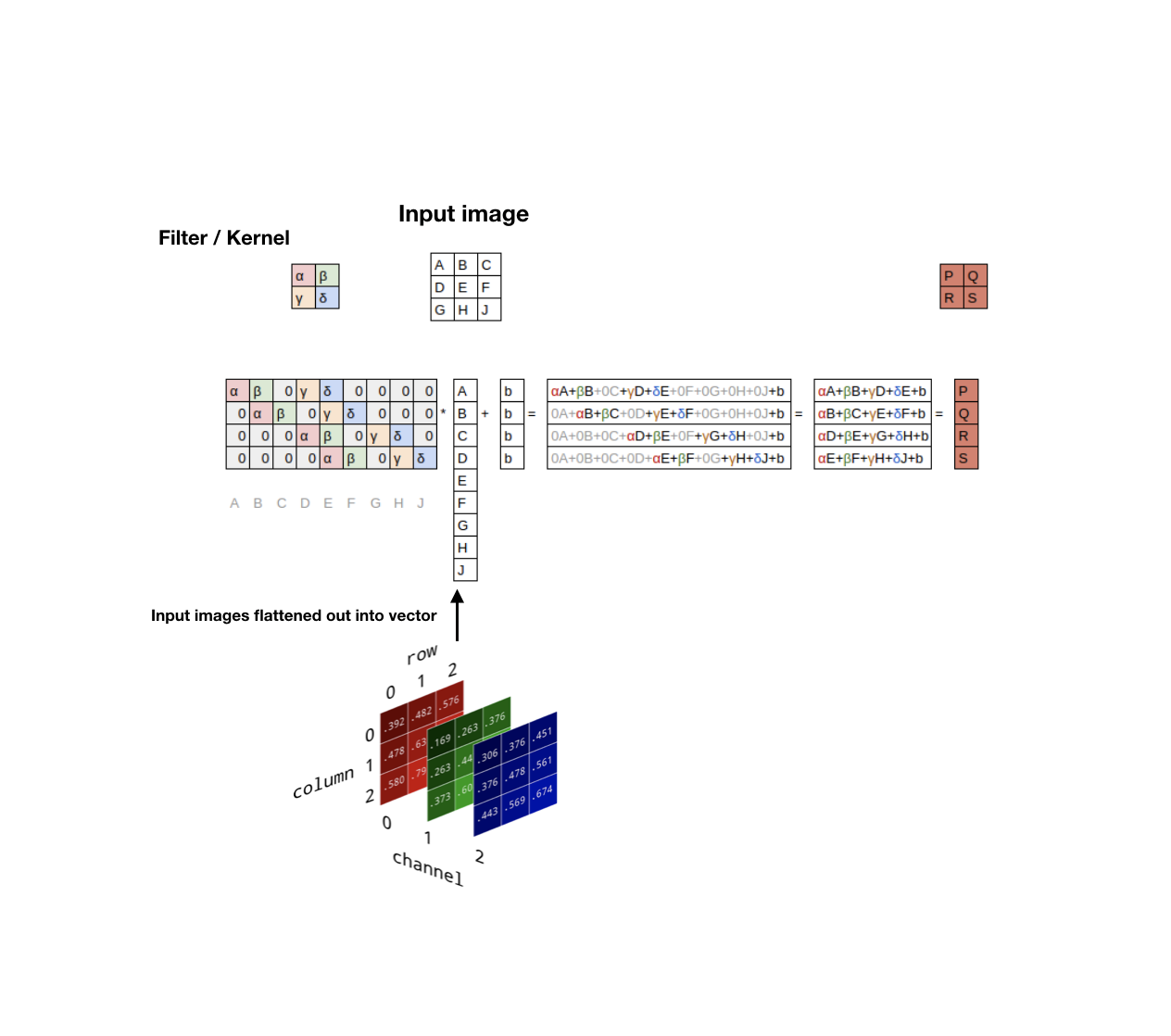
convolution layer needs square image.
as a software developer, be sure to keep refactoring what you’ve implemented. for example, jeremy made stats function
todo [^1] when you don’t understand why the weight shape is 32, 1, 5, 5
torch.nn.modules.conv._ConvNd.reset_parameters??
check pytorch, they don’t handle with default relu ( this could be little different since video was taken at July, 2019)
PyTorch doesn’t handle well with initialization.
li = nn.Conv2d(1, nh, 5)
rec_fs = li.weight[0,0].numel()
this way we can get the size of receptive filter, number of element.
How we calculate the receptive fan_in and fan_out at convolutional layer.
function gain(0), gain(0.1), … , gain(math.sqrt(5.)) <- pytorch’s doing with
and also they are using kaiming_unit not normal
And jeremy compared his function and pytorch function.
02b_initializing.ipynb
You are out of keep tracking the numbers(=parameters) that matter
Some tricky initialization researches and methods would make your own experiment hard. video
shape of the weight was up-side down, and it was because of some code which was 7 years code. Lua library things.
03_minibatch_training.ipynb
Changing mse -> cross entropy
first, we will change mse to cross_entropy since it’s categorical variable.
note how novel jeremy’s nll function is </br>
logsumexp trick(numerical stability trick) : when you are handling the number which is very big,
log softmax in negative log likelihood is called cross entropy.
refactoring nn.module
- manually going through weight and bias
- grab all of the parameters of model at once -> DummyModule() will do that
dunder __setattr__ : will call this method, when you assigned anything inside self,
[^2] the attribute name doesn’t start with underscore,/ because if it does, it might be \_modules and then it’s going to be like a recursive loop. and also it’s not some internal private stuff.
And these refactoring things are same with nn.Module
Q1: what code Jeremy exchanged to super().__init__() in SequentialModel class?
Q2: what code Jeremy exchanged to nn.ModuleList(layers)
Q2: what code Jeremy exchanged to nn.SequentialModel(layers)
And if you look on source code, you will find that we didn’t dumbed down the code
Refactoring nn.optim
PyTorch's optim.SGD is doing some significant things including weight_decay, momentum, dampening, nestrov
Two thing that you can learned from his interactive data science experiments.
- when you architect your model, put things that should be checked
- even SGD is theoretically imperfect
- Jeremy used accuracy here, to check those things.
- didn’t use seed (very intentionally)
- we can observe variations when we run the model different times
- reproducible science
- BUT, not on your model when you want to develop intuitive understanding of your model!
Dataset and DataLoaders
To avoid iterate separately through mini batches of x and y values!
Dunders
DataLoader
initialize class with datasize and batchsize
Use dunder iter
coroutine function (when jeremy tried to explain iteration
To the people who feels these processes are so hard
Maybe you want to read the code very intuitively, and refactor it like expert,
but it’s very hard to maintain and understand the code. And also this ability is key to be a researcher, because if you want try something, you should know how to do it.
Random sampling
one of the remained problem is we see the training data are in order, meaning at every epoch, we are giving our model the exactly same bunch of our data with previously given.
Sampler class, which has init and iter.
- this structure can be used often when you’re doing streaming computations (so that you out of memory), way of looping through something which is itself for co-routine, and then yielding something which does other things to that.
If you want to use different stacked version of tensor (e.g. padded tensor) you can use different kind of collate function.
Pytorch DataLoader
which does exactly same thing that we’ve done
But unfortunately, they don’t have function that grasp just one sample of data. but basically our api and pytorch are doing same thing.
One thing we didn’t implemented which is in pytorch, num_workers [^3]
Validation
Don’t forget to call model.train() / model.eval() before you start train/validation, since technique like batchnorm, dropout should be applied to training only, not validation/evaluation data. [^4]
Also, we don’t backward with validation data, but just keep tracking of accuracy and loss in batch.
Question: Are these validation results correct if batch size varies? Lecture video
✔︎ Why this could be problem?
we have 2 batches and one minibatch size of 1000, and the other size of 1, then you must add up with weighted average, not just dividing by 2!
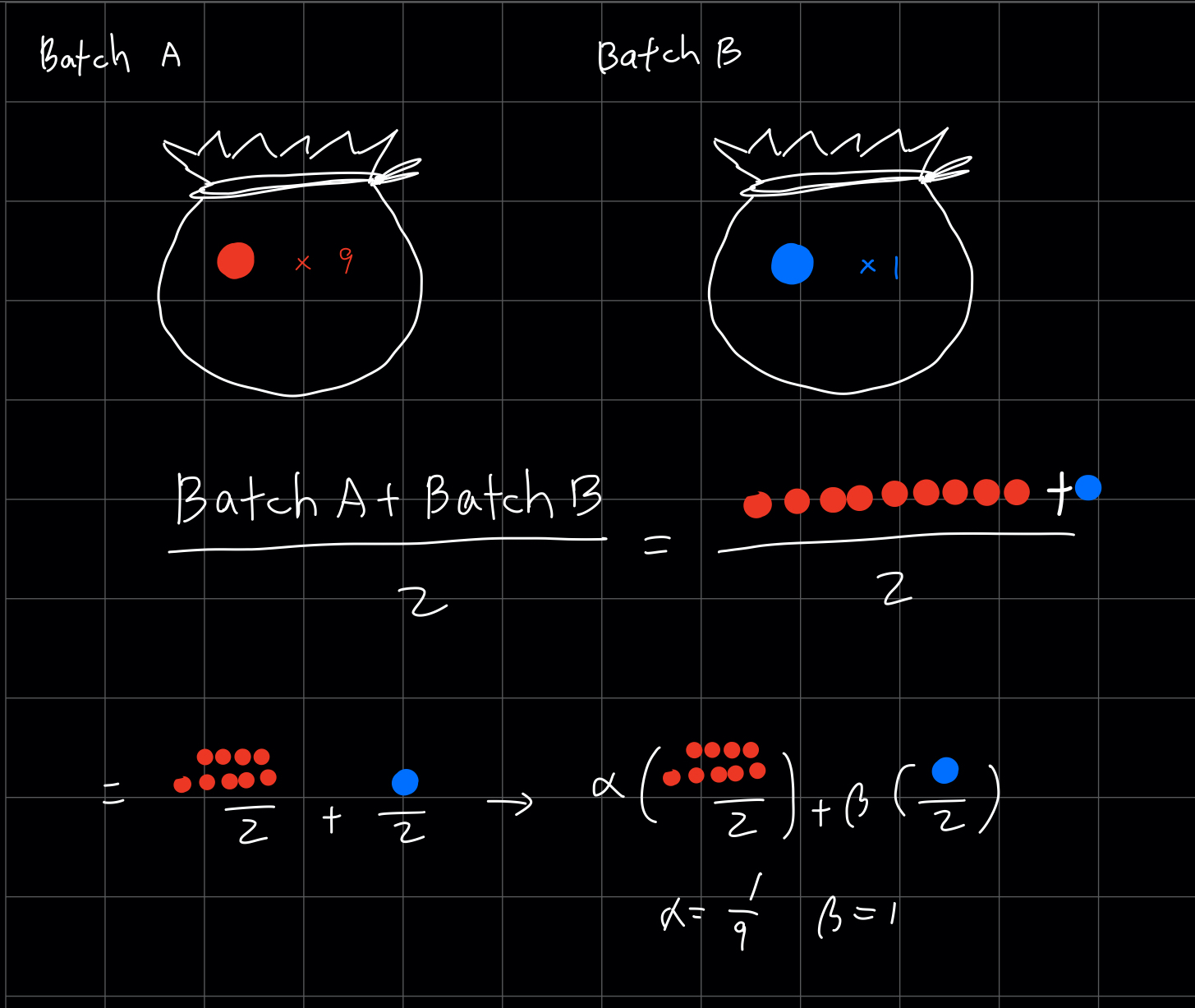
Be careful, lots of (almost most of) library does things like this without considering size of batch (of course fast.ai is doing well :wink)
when you see the get_dls function, you will notice that batch size in validation data is twice of the train’s -> Since we don’t have to save our backward gradients at validation data set, we have much more space!
Q1. Why do we have to zero our gradient at PyTorch?
J: just before using parameters and optim, we made the gradients zero (regardless of pytorch). You can control easily, when to optimize or gather up gradients. For example, suppose you just can have size 2 of mini-batch (matter of GPU, whatever). Then if you want to double the actual batch size of learning, you just run the optimizer and zero grad for every 2 iterations of batch_size (or you can get three times of batch size when you do it for every 3 iterations).
This is called gradient accumulation, and it depends on your model.
04_callbacks.ipynb
Sylvain’s talk, An Infinitely Customizable Training Loop Video, Slide
Why this callback is special? (since every library has callback)
fastai has callback for every steps of train! (i.e. modeling, loss function, calculating gradients, iteration, etc)
Advantage, when you give parameters in package
- pass them at once
- make factory method (or kind of that things)
- add some more function that you need to get intuition regarding params (Or, if API, can give options to users)
First fit() function!
-> DataBunch()
- be sure to lender
c, which is a value of output, since it doesn’t depends on shape of tensor!
Learneris just a storage, not having any logic in that.
and nowfitfunction changed to just getting epoch, learn!
Callback Handler
Notice repeated parameter of cb, meaning they need to some common state.
Implement by yourself and check how much it became elegant code.
How?
- Callback becomes short for
__getattr__in handler(i.e. trainevalcallback), optional for callbackhandler to inherit when it can’t fine callback __call__in Runner, to unify object function calling callback
Q2. Difference bw hooks in pytorch and callback in fastai?
we gonna do hooks very shortly, and make sure that there’s no way to add callback when you already did forward pass, meaning you can only use hooks in pytorch module which is much more restrictive than fastai. and we will look through them soon.(maybe lesson 10)
Runner
order : int (private) in callback class - you may want to order some training process in particular way, e.g. to do specific experiments
(jeremy becomes so fast from here T.T)
class AvgStats
call train, valid stats stuff when we start, and reset that value when epoch finished, while accumulating the stats we need.
- you can see in
accumulatefunction implemented to considered different size of mini batch
Question3 : Runner’s dunder call exits early when the first callback returns true, and why is that
J: When I designed callback first, the most awkward thing was basically python returns none if there’s nothing you return and that means false. so I must add additional setting which makes model keep going on when they return nothing.
That’s why you would see basic(default) condition isif not, not if. So the function became having condition which cancels processing when it returnstrue(* true means stop!!!)
partical is function which returns function
fastai version part2 has some choices that you can select how much dig deep inside of the specific part.
The essential things is thefitfunction
- stores n_epochs, kind of learner
- calls different callbacks at each time
remember to visit fast ai document, and also see what’s going on through source code.
05_anneal.ipynb
Motivation
- when you have to have constant learning rate
- to see ‘just one batch’ learning is going on is a good way to check performance, mechanics and dynamics of your model.
- good annealing is very impt. to have your first batch being done well.
So we will use our callback, do a annealing
We can change learning rate is quite easy, just call partial
Question4: what is your typical debugging processing?
Use debugger. I use jupyter magic command, %debug, when things are deviating from what I expected. Add setting underscore somewhere suspected. and everything is going well, then looking at the shape of the tensors. Usually
Noneor zeros or whatever. Debugging is not difficult for me, since pytorch established that very well, and step back and examining your assumption one again is also a good way.
Hyper parameter scheduling
- you should schedule everything if you want to get results somewhat successful
- e.g. momentum, drop out, amount of data augmentation, learning rate,
- It’s very rare that you want to use same hyper parameter during all the training process
class ParamsScheduler
- get epoch, which is float, and in this case it decides learning rate.
- layer groups(fastai), parameter groups(pytorch), which represent different hyper parameters between layers.
def sched_lin gets pos only as argument
we can simplify using decorator.
decorator is the function that returns function. And you check using shift+tab is shows parameters as (start, end) since it decorator changed that function.
f = sched_lin(1,2)
f(0.3)
this code tells us what’s going on the way of 30% being done.
(*julia - macro)
you can’t plot the pytorch tensor since they don’t have ndim attribute that matplotlib requires.
BUT, since python is dynamic you can change everything…….. (sometimes this makes trouble…)
we can also combine several schedulers together, which use different mechanics.
And cosine one-cycle lr do this very well.
# Next time - we will finally use GPU - check before what we should additionally attach to use GPU - deep inside of Convolution. - transformation - add callbacks between layers, and then use pytorch hooks, and plot what's going on. - find the way how to enhance them using our analytics - batch_norm, data_block api, optimizers, transforms.
--- [^1]: Study `conv-example.xlsx' excel [^2]: https://youtu.be/AcA8HAYh7IE?t=2996 [^3]: find related PyTorch document [^4]: Jeremy said if we don't separate train/valid, we will get awful results when test. DO IT BY YOURSELF!
 CS224N | Winter2019 | Assignment 3 Solution
CS224N | Winter2019 | Assignment 3 Solution