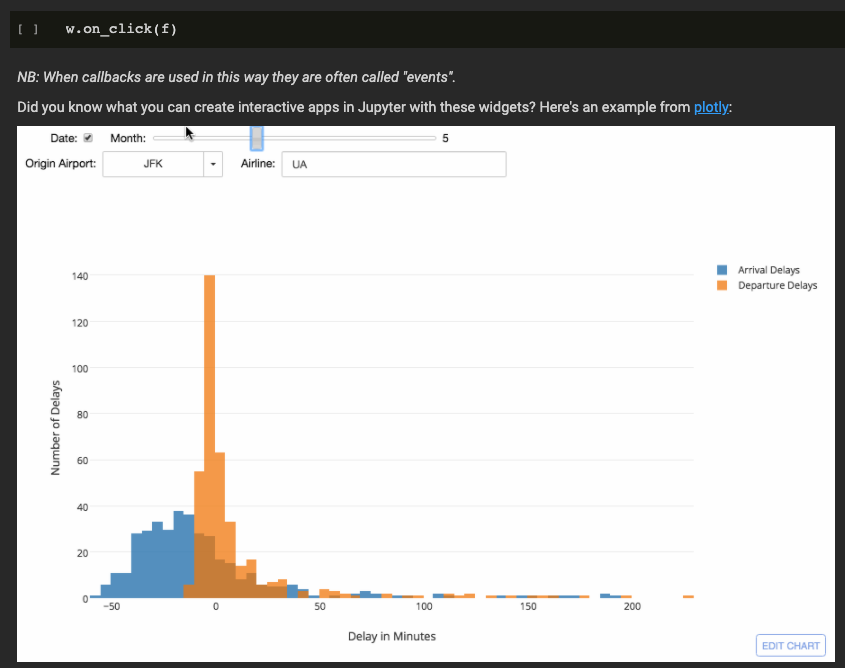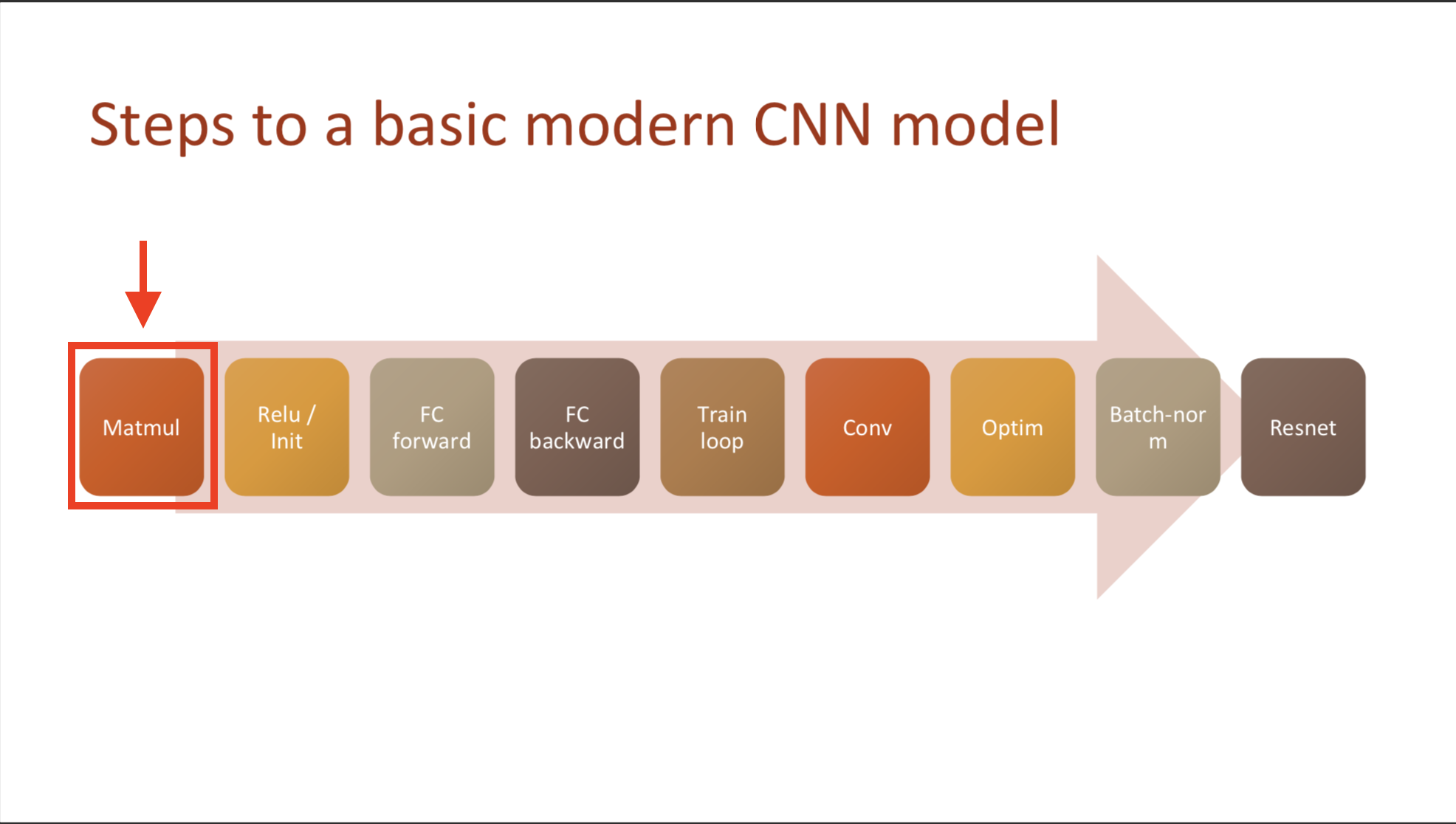
Quick code manual (to review), https://github.com/fastai/course-v3/tree/master/nbs/dl2/01 & 02
- matrix multiplication function
- classic matmul (3 for loop)
- use elementwise (2 for loop)
- use broadcating (1 for loop)
- use einsum(torch’s) (0 for loop)
- forward and backward pass function
- mse, relu, linear function’s gradient
- Layers as classes
- Relu, Linear, MSE -> Model
- call & backward
- Relu, Linear, MSE -> Model
- Module.forward()
- Module -> Relu, Linear, MSE
- Model call & backward
Question: difference bewteen layers as classes & module.forward()
- nn.Linear and nn.Module
- nn.Module -> Model
- nn.Linear,LeLU
Todo: kaiming_normal deprecated
- function
get_data- return torch tensor datasets
- class Dataset
- initialize with x, y
- length, getitem
- function
get_dls- validation set’s batchsize : twice than train
- why should we shuffle train data?
- class DataBunch
- train_ds, valid_ds as property to get item
- function get_model
- return model & optimizer function
- use torch.nn library
- class Learner
- saves model, opt, loss, data
- function create_learner
- return Leaner instance
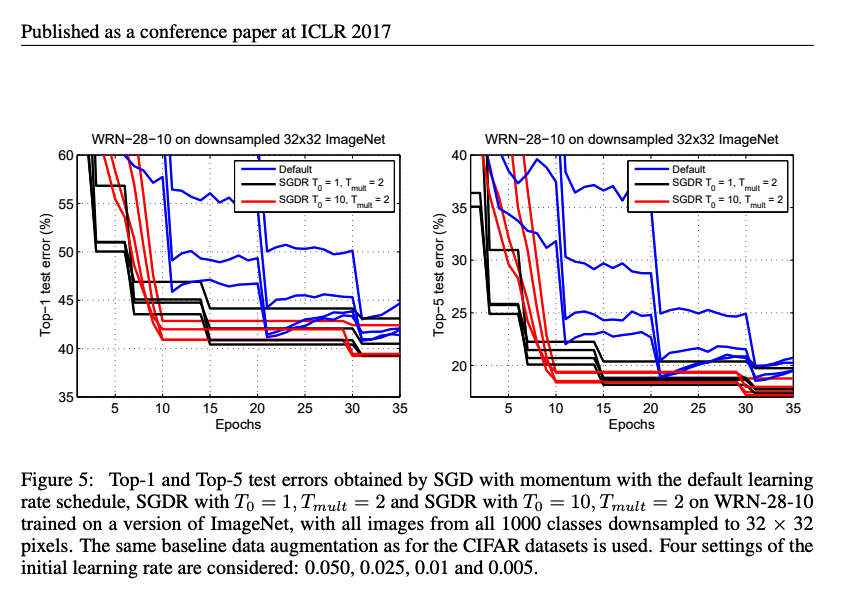 Part2 lesson 10, 05 anneal | fastai 2019 course -v3
Part2 lesson 10, 05 anneal | fastai 2019 course -v3