Direct link to answer: link
ConvNet
🎮 Q0: Preprare data (and normalize it), dataset, databunch.
🎮 Q1: Implement Lambda layer that can take a basic function and convert it to a layer you can put in nn.Sequential.
🎮 Q2: define ‘get_cnn_model’ which returns composed cnn layers with nfs = [ni, ni*8, ni*8*2, ni*8*2*2, ni*8*2*2] using previously defined Lambda converter. [^4]
📝 Q3: Why assign kernel size 5 only for first layer?
Cuda
🎮 Q4: Implement Callback which transfers model device to cuda. Compare time when you trained with CPU.
Refactor
🎮 Q5: New get_cnn_model function which eliminates replicacy of conv and relu by regrouping conv and relu with a function.
🎮 Q6: Implement Callback which resize mnist when we start batch training.
🎮 Q7: Implement function which gets any list of n_filters and renders layers and model.
🎮 Q8: make get_runner which gives us everything we need for training
Hooks
🎮 Q9: Suppose we want to do some telemetry, and want the mean and std to be saved in for each layers. Make your own model class which saves the statistisc of activation and chains output.
Hint: You can make customized Sequential model class, which connects layers in a cascading way.
🎮 Q10: Train the model with customized model and plot the activation statistics.
🎮 Q11: For this time, let’s use pytorch hooks. A hook can be added to any nn.Module and it will be called when a layer is executed during forward / backward pass. (i.e. forward, backward hook)
Hint: A hook needs to be a function that takes three argments: (1) module, (2) input, (3) output
🎮 Q12: This time, we use pytorch’s hook but make it as a class which contains removal function as well. This is important since the memory won’t be properly released when the model is deleted. (i.e. reference of the hook can remain though you remove the model.) Train the model with customized hook class and remove it after plotting.
🎮 Q13 (optional): Hooks class to manage several hooks in our customized container.
🎮 Q14 : Plot histogram of the model activations.
Hint: re-initialize append_stats funciton
📝 🎮 Q15: Pull out first batch of input data and see the activation of first layer. Why do you think teh tensor size is 108, 40?
🎮 Q16: Implement generic/generalized ReLU which can embrace various type of activations (e.g., leaky). Define new model using customized leaky relu and see statistics of activations.
🎮 Q17: Plot proportion of zero in activation.
A0
!git clone https://github.com/fastai/course-v3
%cd /content/course-v3/nbs/dl2
%load_ext autoreload
%autoreload 2
%matplotlib inline
from exp.nb_06 import *
%cd /content/
def get_data():
path=Path('/content/mnist.pkl.gz')
with gzip.open(path) as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
return map(tensor, (x_train, y_train, x_valid, y_valid))
x_train, y_train, x_valid, y_valid = get_data()
train_ds, valid_ds = Dataset(x_train, y_train), Dataset(x_valid, y_valid)
bs, nh = 512, 50
c = y_train.max()+1
loss_func = F.cross_entropy
data = DataBunch(*get_dls(train_ds, valid_ds, bs), c)
cbfs = [Recorder,
partial(AvgStatsCallback, accuracy),
partial(BatchTransformXCallback, mnist_view)]
nfs = [8, 16, 32, 64, 64]
learn, run = get_learn_run(nfs, data, 0.4, conv_layer, cbs=cbfs)
run.fit(5, learn)
A1
class Lambda(nn.Module):
def __init__(self, func):
super().__init__()
self.func = func
def forward(self, x):
return self.func(x)
A2
def minist_resize(x): return x.view(-1, 1, 28, 28)
def flatten(x): return x.view(x.shape[0], -1)
def get_cnn_model(data):
return nn.Sequential(
Lambda(mnist_resize),
nn.Conv2d( 1, 8, 5, padding=2, strite=2), nn.ReLU(),#tranform 25 pixels to 8 pixels #14
nn.COnv2d( 8,16, 3, padding=1, stride=2), nn.ReLU(), #7
nn.COnv2d(16,32, 3, padding=1, stride=2), nn.ReLU(), #4
nn.COnv2d(32,32, 3, padding=1, stride=2), nn.ReLU(), #2
nn.AdaptiveAvgPool2d(1),
Lambda(flatten)
nn.Linear(32, data.c)
)
A3
If we start 3 kernels and 8 channels, then actually we are converting 9 (3 by 3) to 8, and this means we are actually reordering information (numbers more all less same).
In a similar vein, for example, when we have 3 kernels and 32 channels with normal image, then we are converting 27 (3 by 3 by 3) pixels to 32, and this means we are loosing information.
On the other hand, if we change to 5 kernels, we convert 125 pixels to 32, and this gurantee abstraction of essence information.
A4
class CudaCallback(Callback):
def begin_fit(self): self.model.cuda()
def begin_batch(self): self.run.xb, self.run.yb = self.xb.cuda(), self.yb.cuda() [^1]
# compare with cpu
cbfs.append(CudaCallback)
model = get_cnn_model(data)
opt = optim.SGD(model.parameters(), lr=0.4)
learn = Learner(model, opt, loss_func, data)
run = Runner(cb_funcs=cbfs)
%time run.fit(3, learn)
A5
def conv2d(ni, nf, ks=3, stride=2):
return nn.Sequential(
nn.Conv2d(ni, nf, ks, padding=ks//2, stride=stride), nn.ReLU())
A6
class BatchTransformXCallback(Callback):
_order=2
def __init__(self, tfms): self.tfms = tfms
def begin_batch(self): self.run.xb = self.tfms(self.xb)
def view_tfm(*size):
def _inner(x): return x.view(*((-1,)+size)) # -1 (-1, 28, 28)
return _inner
mnist_view = view_tfm(1, 28, 28)
cbfs.append(partial(BatchTransformXCallback, mnist_view))
A7
nfs = [8, 16, 32, 32]
def get_cnn_layers(data, nfs):
nfs = [1] + nfs
return [
conv2d(nfs[i], nfs[i+1], 5 if i==0 else 3)
for i in range(len(nfs)-1)
] + [nn.AdaptiveAvgPool2d(1), Lambda(flatten), nn.Linear(nfs[-1], data.c)]
def get_cnn_model(data, nfs): return nn.Sequential(*get_cnn_layers(data, nfs))
A8
def get_runner(model, data, lr=0.6, cbs =None, opt_func = None, loss_func = F.cross_entropy):
if opt_func is None: opt_func = optim.SGD
opt = opt_func(model.parameters(), lr = lr)
learn = Learner(model, opt, loss_func, data)
return learn, Runner(cb_funcs = listify(cbs))
model = get_cnn_model(data, nfs)
learn, run = get_runner(model, data, lr= 0.4, cbs = cbfs)
model
run.fit(1, learn)
A9
class SequentialModel(nn.Module):
def __init__(self, *layers):
super().__init__()
self.layers = nn.ModuleList(layers)
self.act_means = [[] for _ in layers]
self.act_stds = [[] for _ in layers]
def __call__(self, x):
for i, l in enumerate(self.layers):
x = l(x)
self.act_means[i].append(x.data.mean())
self.act_stds [i].append(x.data.std())
return x
def __iter__(self): return iter(self.layers)
A10
model = SequentialModel(*get_cnn_layers(data, nfs))
learn, run = get_runner(model, data, lr=0.9, cbs = cbfs)
run.fit(2, learn)
for l in model.act_means(): plt.plot(l)
plt.legend(range(len(model.layers)))
for l in model.act_stds(): plt.plot(l)
plt.legend(range(len(model.layers)))
A11
model = get_cnn_model(data, nfs)
learn, run = get_runner(model, data, lr = 0.5, cbs = cbfs)
act_means = [[] for _ in model]
act_stds = [[] for _ in model]
def append_stats(i, m, inp, out):
act_means[i].append(out.data.mean())
act_stds [i].append(out.data.std())
for i, m in enumerate(model): m.register_forward_hook(partial(append_stats, i))
run.fit(1, learn)
A12
def children(m): return list(m.children())
class Hook():
def __init__(self, m, f): self.hook = m.register_forward_hook(partial(f, self))
def remove(): self.hook.remove() # [^3]
def __del__(self): self.remove()
def append_stats(hook, mod, inp, outp):
if not hasattr(hook, 'stats'): hook.stats = ([], [])
means, stds = hook.stats
means.append(outp.data.mean())
stds.append(outp.data.std())
model = get_cnn_model(data, nfs)
learn, run = get_runner(model, data, lr=0.5, cbs=cbfs)
hooks = [Hook(l, append_stats) for l in children(model[:4])]
run.fit(1, learn)
for h in hooks:
plt.plot(h.stats[0]) #mean
h.remove()
plt.legend(range(4))
A13
class ListContainer():
def __init__(self, items): self.items = listify(items)
def __getitem__(self, idx):
if isinstance(idx, (int, slice)): return self.items[idx]
if isinstance(idx[0], book):
assert len(idx) == len(self) #bool mask
return [item for bool_i, item in zip(idx, self.items) if bool_i]
return [self.items[i] for i in idx]
def __len__(self): return len(self.items)
def __iter__(self): return iter(self.items)
def __setitem__(self, i, o): self.items[i] = o
def __delitem__(self, i): del(self.items[i])
def __repr__(self):
res = f'{self.__class__.__name__} ({len(self)} items)\n{self.items[:10]}'
if len(self)> 10: res = res[:-1] + '...]' #[^2]
return res
from torch.nn import init
class Hooks(ListContainer):
def __init__(self, modules, f): super().__init__([Hook(module, f) for module in modules])
def __enter__(self, *args): return self
def __exit__(self, *args): self.remove()
def __del__(self): self.remove()
def __delitem__(self, i):
self[i].remove()
super().__delitem__(i)
def remove(self):
for h in self: h.remove()
model = get_cnn_model(data, nfs).cuda()
learn, run = get_runner(model, data, lr=0.9, cbs=cbfs)
with Hooks(model, append_stats) as hooks:
run.fit(2, learn)
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(15, 6))
ax0.title.set_text('10 batch, mean')
ax1.title.set_text('10 batch, std')
for h in hooks:
ms, ss = h.stats
ax0.plot(ms[:10])
ax1.plot(ss[:10])
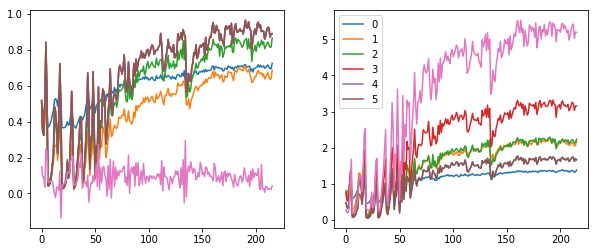
plt.legend(range(6))
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(15, 6))
for h in hooks:
ms, ss = h.stats
ax0.plot(ms)
ax1.plot(ss)
plt.legend(range(6))
A14
def append_stats(hook, mod, inp, outp):
if not hasattr(hook, 'stats'): hook.stats = ([], [], [])
means, stds, hists = hook.stats
means.append(outp.detach().mean().cpu())
stds .append(outp.detach().std().cpu())
# https://pytorch.org/docs/stable/generated/torch.histc.html
hists.append(outp.detach().cpu().histc(40, 0, 10))
model = get_cnn_model(data, nfs)
learn, run = get_runner(model, data, lr=0.9, cbs = cbfs)
with Hooks(model, append_stats) as hooks: run.fit(1, learn)
# https://pytorch.org/docs/stable/generated/torch.log1p.html
def get_hist(h): return torch.stack(h.stats[2]).t().float().log1p()
fig, axes = plt.subplots(3, 2, figsize=(20,10))
# axes.shape, axes.flatten().shape
for ax, h in zip(axes.flatten(), hooks[:6]):
# https://matplotlib.org/stable/tutorials/intermediate/imshow_extent.html
ax.imshow(get_hist(h), origin='lower')
ax.axis('off')
plt.colorbar(img, ax = ax)
# plt.legend()
plt.tight_layout()
A15
- 108: number of iteration, 40: number of histogram bins, see https://pytorch.org/docs/stable/generated/torch.histc.html for more information.
xb, yb = next(iter(data.train_dl))
# xb.shape, yb.shape
xb = xb.view(-1, 1, 28, 28)
model[0](xb).detach().cpu().histc(40, 0, 10)
- the activation is not exactly matched to
hooks[0].stats[2][0]because batches are shuffled in training set.
A16.
class GeneralRelu(nn.Module):
def __init__(self, leak=None, sub = None, maxv = None):
super().__init__()
self.leak, self.sub, self.maxv = leak, sub, maxv
def forward(self, x):
x = F.leaky_relu(x, self.leak) if self.leak is not None else F.ReLU(x)
if self.sub is not None: x.sub_(self.sub)
if self.maxv is not None: x.clamp_max_(self.maxv)
return x
def get_cnn_layers(data, nfs, layer, **kwargs):
nfs = [1] + nfs # [1] represents Channel of mnist dataset
return [
layer(nfs[i], nfs[i+1], 5 if i==0 else 3, **kwargs)
for i in range(len(nfs)-1)
] + [nn.AdaptiveAvgPool2d(1), Lambda(flatten), nn.Linear(nfs[-1], data.c)]
def conv_layer(ni, nf, ks =3, stride=2, **kwargs):
return nn.Sequential(
nn.Conv2d(ni, nf, ks, padding=ks//2),
GeneralRelu(**kwargs)
)
def get_cnn_model(data, nfs, layer, **kwargs):
return nn.Sequential(*get_cnn_layers(data, nfs, layer, **kwargs))
def append_stats(hook, mod, inp, out):
if not hasattr(hook, 'stats'): hook.stats = ([], [], [])
means, stds, hists = hook.stats
means.append(out.detach().cpu().mean())
stds .append(out.detach().cpu().std())
hists.append(out.detach().cpu().histc(bins = 40, min=-7, max=7))
model = get_cnn_model(data, nfs, conv_layer, leak = 0.1, sub = 0.4, maxv=6.)
def init_cnn(model, uniform = False):
f = init.kaiming_uniform_ if uniform else init.kaiming_normal_
fig, axes = plt.subplots(4, 2, figsize=(20,10))
for mi, l in enumerate(model):
if isinstance(l, nn.Sequential):
axes[mi][0].plot(l[0].weight[0, :].detach().flatten())
f(l[0].weight, a = 0.1)
l[0].bias.data.zero_()
axes[mi][1].plot(l[0].weight[0, :].detach().flatten())
init_cnn(model)
learn, run = get_runner(model, data, lr=0.9, cbs = cbfs)
with Hooks(model, append_stats) as hooks: run.fit(1, learn)
fig, (ax0, ax1) = plt.subplots(1, 2, figsize = (10, 4))
for h in hooks:
ms, ss, _ = h.stats
ax0.plot(ms[:10])
ax1.plot(ss[:10])
h.remove()
plt.legend(range(len(hooks)))
fig, (ax0, ax1) = plt.subplots(1, 2, figsize = (10, 4))
for h in hooks:
ms, ss, _ = h.stats
ax0.plot(ms)
ax1.plot(ss)
h.remove()
plt.legend(range(len(hooks)))
fig, axes = plt.subplots(3, 2, figsize=(20,10))
# axes.shape, axes.flatten().shape
for ax, h in zip(axes.flatten(), hooks[:6]):
img = ax.imshow(get_hist(h), origin='lower')
hi = get_hist(h)
# bar = plt.colorbar(ax)
ax.axis('off')
plt.colorbar(img, ax = ax)
plt.tight_layout()
hi.t().max(-1).values, hi.t().min3(-1).values
A17
def get_min(h):
h1 = torch.stack(h.stats[2]).t().float()
return h1[19:22].sum(0) / h1.sum(0)
fig, axe = plt.subplots(2, 2, figsize = (20, 10))
for ax, h in zip(axes.flatten(), hooks[:4]):
ax.plot(get_min(h))
ax.set_ylim(0, 1)
plt.tight_layout()
footnote
Conv2d dilation
Conv2d filter groups
[^1]: What’s difference between self.yb.cuda() and self.run.yb.cuda()? why we assign left one to the right side?
[^2]: Can we add string here?
[^3]: why there’s __del__ magic method and it again call remove function of hook? Why don’t we directly remove hook?
[^4]: Why nn.Maxpool2d(1) returns tensor size [batchsize, n_channel, 2, 2], while nn.AdaptiveAvgPool2d(1) returns [batchsize, n_channel, 1, 1]?
 Part2 lesson 10, 5ab, closure&decorator, early stopping
Part2 lesson 10, 5ab, closure&decorator, early stopping