Image source: fastai-data-block
(Finally) we moved on to imagenette whose entire dataset might unfit to your RAM, so we grab each mini-batch as we need it.
Q1. monkey-patch pathlib.Path (python standard lib) to add a method which returns all elements in directory.
- hint: remember first argument of the method is fixed to instance it-‘self’
Q2. Plot each class’s first image and its size.
- hint: if you want to draw multiple-col/row, do not slice axes array but flatten ax.
Q3. Attain all extensions of filename for image, text, audio.
- hint: use python standard library’s database.
Q4. Implement get_files which walks through all directories and grab image files. Test it with getting tench and all files.
- hint:
get_filessort out corresponding path and filenames and_get_filesrender actual file name list.
Q5. Implement ItemList which stores image file list and ImageList which actually access item object.
Q6. Implement split_by_func which divides using function.
- hint: train/valid information is given as a name of folder.
Q7. Now extend previous functions to SplitData class which separate train / valid dataset and returns distinct itemlists. 1
Q8. When should labeling(processor) has to work? explain its process with some examples.
Q9. Convert image to rectangular tensor
- hint: 1) fix image size 2) convert to bytes 3) convert to tensor
Q10. (finally) build a databunch and test all processes at once. Which processes do you need to make databunch from data path?
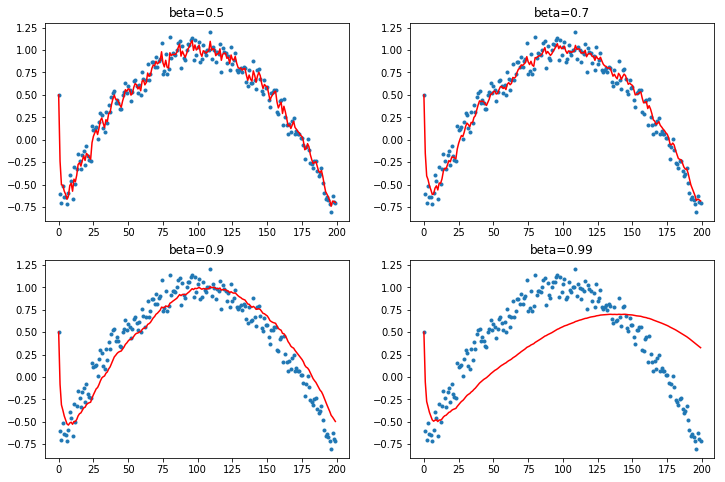
Q11. Let us change normalize unit of the training data. Now use the statistics of a batch (not entire training data).
(optinal) Q12. Fix the conv layers to use three 3x3 convs at first layer and progressively increase to 64.
A1.
from pathlib import Path
Path.ls = lambda x: list(x.iterdir())
A2
train_dir = [i for i in (path/'train').iterdir() if i.is_dir()]
fig, axes = plt.subplots(2, 5, figsize=(30, 20))
for idx, (class_path, ax) in enumerate(zip(train_dir, axes.flatten())):
img_path = class_path.ls()[0]
img = PIL.Image.open(img_path)
ax.set_title(f"{numpy.array(img).shape}")
ax.imshow(img)
A3
get_extensions= lambda x: set(k for k, v in mimetypes.types_map.items() if v.startswith(f'{x}/'))
list(map(get_extensions, ['image','text','audio']))
A4
import os
def setify(o): return o if isinstance(o, set) else set(listify(o))
image_extentions = get_extensions('image')
def _get_files(p, fs, extensions=None):
p = Path(p)
res = [p/f for f in fs if not f.startswith('.')
and ((not extensions) or f'.{f.split(".")[-1].lower()}' in extensions)]
return res
fnames = [f.name for f in os.scandir(tench_path)]
t = _get_files(tench_path, fnames, extensions=image_extensions)
def get_files(path, extensions=None, recurse=False, include=None):
path = Path(path)
extensions = setify(extensions)
extensions = {e.lower() for e in extensions}
if recurse:
res = []
for i,(p,d,f) in enumerate(os.walk(path)): # returns (dirpath, dirnames, filenames)
if include is not None and i==0: d[:] = [o for o in d if o in include]
else: d[:] = [o for o in d if not o.startswith('.')]
res += _get_files(p, f, extensions)
return res
else:
f = [o.name for o in os.scandir(path) if o.is_file()]
return _get_files(path, f, extensions)
t_fns = get_files(tench_path, get_extensions('image'), True)
all_fns = get_files(path, get_extensions('image'), recurse=True)
A5
def compose(x, funcs, *args, order_key='_order', **kwargs):
key = lambda o: getattr(o, order_key, 0)
for f in sorted(listify(funcs), key=key):
x = f(x, **kwargs)
return x
class ItemList(ListContainer):
def __init__(self, items, path='.', tfms=None):
super().__init__(items)
self.path, self.tfms = Path(path), tfms
def __repr__(self): return f'{super().__repr__()}\nPath: {self.path}'
def new(self, items, cls=None):
if cls is None: cls=self.__class__
return cls(items, self.path, tfms=self.tfms)
def get(self, i): return i
def _get(self, i): return compose(self.get(i), self.tfms)
def __getitem__(self, i):
res = super().__getitem__(idx)
if isinstance(res, list): return [self._get(o) for o in res]
return self._get(res)
class ImageList(ItemList):
@classmethod
def from_files(cls, path, extensions=None, recurse=True, include=None, **kwargs):
if extensions is None: extensions = image_extensions
return cls(get_files(path, extensions, recurse=recurse, include=include), path, **kwargs)
def get(self, fn): return PIL.Image.open(fn)
class Transform(): _order=0
class MakeRGB(Transform):
def __call__(self, item): return item.convert('RGB')
def make_rgb(item): return item.convert('RGB')
img_list = ImageList.from_files(path, tfms=make_rgb)
img = img_list[0]; img
A6
def split_by_func(items, f):
"""function returns true when it's train dataset, otherwise false"""
masks = [f(i) for i in items]
# here you'd better to filter explicitly wheter its true , false or none since item can be not train nor the valid.
ts=[img for img, m in zip(items, masks) if m==True]
vs=[img for img, m in zip(items, masks) if m==False]
return ts, vs
def grandparent_splitter(fn, valid_name='valid', train_name = 'train'):
ds = fn.parent.parent.name
return True if ds == train_name else False if ds == valid_name else None
splitter = partial(grandparent_splitter, valid_name = 'val')
trainset, validset = split_by_func(img_list, splitter)
len(trainset), len(validset)
A7
class SplitData():
def __init__(self, train, valid): self.train, self.valid = train, valid
def __getattr__(self, k): return getattr(self.train, k)
def __setstate__(self, data:Any): self.__dict__.update(data)
@classmethod
def split_by_func(cls, il, f):
lists = map(il.new, split_by_fn(il.items, f))
return cls(*lists)
def __repr__(self): return f'{self.__class__.__name__}\nTrain: {self.train}\nValid: {self.valid}\n'
splitdt = SplitData.split_by_func(img_list, splitter)
splitdt.train, splitdt.valid
A8
- Labeling has to be done after splitting train and valid set, because it uses training set information to apply to validation set (and maybe the test set or at inference time on a single item).
- For example, in text, it could be tokenization, numericalization which require to keep track of splitting tokens, hash table of vocab and its index.
- In tabular data, when filling the missing value, the median (or mean, whatever) data we used on tranining data must be applied to validation set also.
- In image data, mapping table of image label to integer should be also applied to validation set.
from collections import OrderedDict
def uniqueify(x, sort=False):
res = list(OrderedDict.fromkeys(x).keys())
if sort: res.sort()
return res
class Processor():
def process(self, items): return items
class CategoryProcessor(Processor):
def __init__(self): self.vocab = None
def __call__(self, items):
if self.vocab is None:
self.vocab = uniqueify(items)
self.otoi = {v:k for k, v in enumerate(self.vocab)}
return [self.proc1(o) for o in items]
def proc1(self, item): return self.otoi[item]
def deprocess(self, idxs):
# we can retrieve only when processed vocabulary exists
assert self.vocab is not None
return [self.deproc1(idx) for idx in idxs]
def deproc1(self, idx): return self.vocab[idx]
def parent_labeler(fn): return fn.parent.name
def _label_by_func(ds, f, cls=ItemList): return cls([f(o) for o in ds.items], path=ds.path)
class LabeledData():
def process(self, il, proc):
# after applying process to il.items, new object of itemlist
return il.new(compose(il.items, proc))
def __init__(self, x, y, proc_x = None, proc_y = None):
self.x, self.y = self.process(x, proc_x), self.process(y, proc_y)
self.proc_x, self.proc_y = proc_x, proc_y
def __repr__(self): return f'{self.__class__.__name__}\nx: {self.x}\ny: {self.y}\n'
def __getitem__(self, idx): return self.x[idx], self.y[idx]
def __len__(self): return len(self.x)
def x_obj(self, idx): return self.obj(self.x, idx, self.proc_x)
def y_obj(self, idx): return self.obj(self.y, idx, self.proc_y)
def obj(self, items, idx, procs):
'''kind of compositional functions, but in this case it restores object'''
isint = isinstance(idx, int) or (isinstance(idx, torch.LongTensor) and not idx.ndim) # right condition ensures 0d tensor
item = items[idx]
for proc in reversed(listify(procs)): #reversed: to restore object from preprocessed one
item = proc.deproc1(item) if isint else proc.deprocess(item)
return item
@classmethod
def label_by_func(cls, il, f, proc_x=None, proc_y=None):
return cls(il, _label_by_func(il, f), proc_x=proc_x, proc_y=proc_y)
def label_by_func(sd, f, proc_x=None, proc_y=None):
'''as label_by_func is classmethod, it initilize (splitted) itemlist of train/valid
note that by using ItemList.new method
'''
train = LabeledData.label_by_func(sd.train, f, proc_x=proc_x, proc_y=proc_y)
valid = LabeledData.label_by_func(sd.valid, f, proc_x=proc_x, proc_y=proc_y)
return SplitData(train, valid)
usage
img_list = ImageList.from_files(path, tfms=make_rgb) #get all imagelist
splitter = partial(grandparent_splitter, valid_name = 'val') #define spilt function which divides train/valid given function
sd = SplitData.split_by_func(img_list, splitter) # split all data to train/valid and save it to instance attr
il = label_by_func(sd, parent_labeler, proc_y=CategoryProcessor()) #make labeld data w.r.t. train's category names
A9
class ResizeFixed(Transform):
_order = 10
def __init__(self, size):
if isinstance(size, int): size = (size, size)
self.size = size
def __call__(self, x):
return x.resize(self.size, PIL.Image.BILINEAR)
def byte_to_tensor(item):
'''bytetensor, resize, rearrange axis'''
res = torch.ByteTensor(torch.ByteStorage.from_buffer(item.tobytes()))
return res.view(*(item.size), -1).permute(2, 0, 1) #as torch gets channel, height, width
byte_to_tensor._order=10
def tensor_to_float(item):
return item.float().div_(255.)
tensor_to_float._order=20
A10
- from data path to databunch (i.e., train_dl + valid_dl)
class DataBunch():
def __init__(self, train_dl, valid_dl, c_in=None, c_out=None):
self.train_dl, self.valid_dl = train_dl, valid_dl;
self.c_in, self.c_out = c_in, c_out
@property #as we have to access dataset through dataloader, here we implement dataset property
def train_ds(self):
return self.train_dl.dataset
@property
def valid_ds(self):
return self.valid_dl.dataset
def databunchify(sd, bs, c_in=None, c_out=None, **kwargs):
dls = get_dls(sd.train, sd.valid, bs, **kwargs)
return DataBunch(*dls, c_in=c_in, c_out=c_out)
- If you inspect the code, all those transformers are applied when you actually access the data
(__getitem__). This is very interesting/briliant way of approaching data.
path = datasets.untar_data(datasets.URLs.IMAGENETTE_160)
transformers = [make_rgb, ResizeFixed(128), byte_to_tensor, tensor_to_float]
imglist = ImageList.from_files(path, tfms=tfms)
- Overall working process
- load datasets’ address in path (line 3)
- assign databunch function to splitdata (Note this method will get
selfas a first argument, thus SplitData(args).to_databunch() won’t requiresd) - split train/valid dataset (line 5)
- transform y label of train (i.e., name of category) to integer as well as valid (line 6)
- group results to databunch(i.e, dataset of train/valid, dataloader of train/valid, number of input/output channel(i.e., channel of image channel, number of y labels))
path = datasets.untar_data(datasets.URLs.IMAGENETTE_160)
transformers = [make_rgb, ResizeFixed(128), byte_to_tensor, tensor_to_float]
img_list = ImageList.from_files(path, tfms=transformers)
SplitData.to_databunch = databunchify
split_data = SplitData.split_by_func(img_list, partial(grandparent_splitter, valid_name='val'))
label_list = label_by_func(split_data, parent_labeler, proc_y=CategoryProcessor())
data = label_list.to_databunch(bs, c_in=3, c_out=10, num_workers=8)
A11
m, s = x.mean((0, 2, 3)), x.std((0, 2, 3))
_m, _s = m.detach().clone(), s.detach().clone()
def normalize_channel(x, mean, std):
# add axis to the last 2 (height, width) as we will normalize through the channel
return (x-mean[..., None, None]) / std[..., None, None]
partial(normalize_channel, mean=_m, std=_s)
cbfs = [partial(AvgStatsCallback, accuracy),
CudaCallback]
cbfs.append(partial(BatchTransformXCallback, norm_imagenette))
A12
nfs = [64, 64, 128, 256]
import math
def prev_pow_2(x): return 2**math.floor(math.log2(x))
def get_cnn_layers(data, nfs, layer, **kwargs):
def f(ni, nf, stride=2): return layer(ni, nf, 3, stride=stride, **kwargs)
l1 = data.c_in
l2 = prev_pow_2(l1*3*3)
layers = [f(l1, l2, stride=1), # c_in, 2* log2(c_in*9)
f(l2, l2*2, stride=1),
f(l2*2, l2*4, stride=1)
]
nfs = [l2*4] + nfs
layers += [f(nfs[i], nfs[i+1]) for i in range(len(nfs)-1)]
layers += [nn.AdaptiveAvgPool2d(1), Lambda(flatten), nn.Linear(nfs[-1], data.c_out)]
return layers
def get_cnn_model(data, nfs, layer, **kwargs):
return nn.Sequential(*get_cnn_layers(data, nfs, layer, **kwargs))
def get_learn_run(data, nfs, lr, layer, cbs=None, opt_func = None, **kwargs):
model = get_cnn_model(data, nfs, layer, **kwargs)
init_cnn(model)
return get_runner(model, data, lr=lr, cbs=cbs, opt_func = opt_func)
sched = combine_scheds([0.3, 0.7], [sched_cos(0.1, 0.3), sched_cos(0.3, 0.05)])
learn, run = get_learn_run(data, nfs, 0.2, conv_layer, cbs=cbfs + [partial(ParamScheduler, 'lr', sched)])
run.fit(3, learn)
A13
def model_summary(run, learn, data, find_all=False):
xb, yb = get_batch(data.valid_dl, run)
device = next(learn.model.parameters()).device
xb, yb = xb.to(device), yb.to(device)
mods = find_modules(learn.model, is_lin_layer) if find_all else learn.model.children()
f = lambda hook, mod, inp, out: print(f"{mod}\n{out.shape}\n")
with Hooks(mods, f) as hooks: learn.model(xb)
-
See fastai forum regarding
__setstate__↩ -
There are two questions. if you debug the process,
img_list[0]callsItemList.__getitem___. Q1, how does it call parent’s method without inheritting super().init()? Second, both IetmList and ImageList havegetmethod but when you callgetmethod inItemlist._get(), it moves back toImageList.getwhile Itemlist also has that method. Why is that? maybe is this because of MRO? ↩ -
here you can render items either form of
img_listorimg_list.items. If you look intoListContainer, slicing works to call PIL.open() while iteration (__iter__) callsiter(items)↩ -
Why should we resize image pixels to 120? Why do we divide it by 255? ↩
-
What is PIL.image.BILINEAR??PIL document ↩
-
Why do we have to use
torch.ByteStorate.from_buffer()? ↩ -
Regarding
num_workersin dataloader, see check_worker_number_rationality ↩
 Part2 lesson 10, 07 batchnorm | fastai 2019 course -v3
Part2 lesson 10, 07 batchnorm | fastai 2019 course -v3